We have a query that has been running for almost two hours on the last of 1,009 reducers in the first reduce phase.
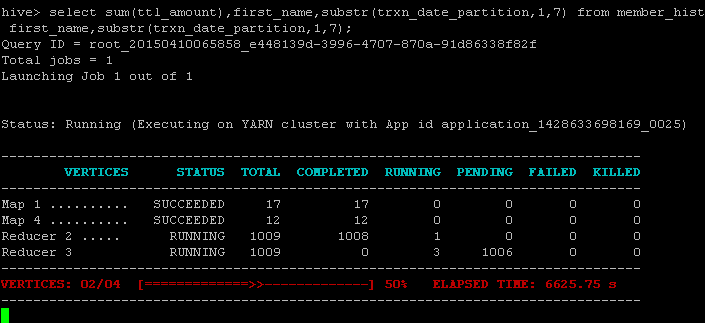
We wanted to gain additional insight into what it was doing, so we first find the node on which the reducer is running. There are probably more elegant ways to do this, but this works. We base our guess on the node using the most CPU.
[root@cmhlpdlkedat15 hive]# for i in {01..12}; do ssh cmhlpdlkedat${i} sar -s 08:00:00 | grep Average; done
Average: all 53.15 0.00 1.49 0.03 0.00 45.34
Average: all 1.68 0.00 1.07 0.05 0.00 97.20
Average: all 1.60 0.00 0.94 0.05 0.00 97.41
Average: all 1.68 0.00 1.00 0.05 0.00 97.27
Average: all 1.33 0.00 0.82 0.04 0.00 97.80
Average: all 1.66 0.00 0.94 0.05 0.00 97.35
Average: all 1.79 0.00 0.90 0.05 0.00 97.27
Average: all 2.89 0.00 1.29 0.06 0.00 95.76
Average: all 1.82 0.00 1.07 0.05 0.00 97.06
Average: all 1.82 0.00 0.93 0.71 0.00 96.54
Average: all 1.48 0.00 0.99 0.04 0.00 97.50
Average: all 1.56 0.00 0.86 0.04 0.00 97.54
[root@cmhlpdlkedat15 hive]#
We then log into that server, and find the thread using the most CPU…
[root@cmhlpdlkedat01 ~]# ps -eLf | awk '{print $2,$4,$9}' | sort -k +3 | tail -5;sleep 5;ps -eLf | awk '{print $2,$4,$9}' | sort -k +3 | tail -5
1795 1862 00:36:28
13649 13656 00:59:33
1795 1808 01:02:08
3393 3412 01:18:38
PID LWP TIME
1795 1862 00:36:28
13649 13656 00:59:33
1795 1808 01:02:08
3393 3412 01:18:42
PID LWP TIME
After five seconds, we see it is PID 3412…
[root@cmhlpdlkedat01 ~]# ps -eLf | grep 3412 yarn 3393 3380 3412 79 26 06:58 ? 01:18:48 /usr/jdk64/jdk1.7.0_45/bin/java -server -Djava.net.preferIPv4Stack=true -Dhdp.version=2.2.0.0-2041 -XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -XX:+UseNUMA -XX:+UseParallelGC -server -Xmx410m -Djava.net.preferIPv4Stack=true -XX:NewRatio=8 -XX:+UseNUMA -XX:+UseParallelGC -XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -Dlog4j.configuration=tez-container-log4j.properties -Dyarn.app.container.log.dir=/mnt/hdfs/hadoop/yarn/log/application_1428633698169_0025/container_1428633698169_0025_01_000004 -Dtez.root.logger=INFO,CLA -Djava.io.tmpdir=/mnt/hdfs/hadoop/yarn/local/usercache/root/appcache/application_1428633698169_0025/container_1428633698169_0025_01_000004/tmp org.apache.tez.runtime.task.TezChild 172.27.2.57 43015 container_1428633698169_0025_01_000004 application_1428633698169_0025 1 root 27426 26643 27426 0 1 08:37 pts/0 00:00:00 grep 3412
We then trace the system calls on this PID, looking only for read calls…
[root@cmhlpdlkedat01 ~]# strace -p 3412 -o t.txt -e trace=read
We see that file descriptor 2231 is being read, and we can even see dates in the input (2015-03-24)…
[root@cmhlpdlkedat01 ~]# head -20 t.txt read(2231, "2015-03-24\0\0\0\27\0\0\0\4\0\0\0\0\0\0\0\17\3\0\1\0\n2"..., 131072) = 131072 read(2232, "\340&\17\350\243\240\371\271\352d\217\7\373\245zLW$z\25\263m\207\313\226u\342\16\\\242\377s"..., 4096) = 4096 read(2231, "\4\0\0\0\0\0\0\0\20\3\2\2\24\f\n2014-12-03\0\0\0\30\0\0\0"..., 131072) = 131072 read(2231, "15-03-11\0\0\0\30\0\0\0\4\0\0\0\0\0\0\0\20\3\2\2\31\242\n20"..., 131072) = 131072
…so we find the actual filename for this descriptor, and tail it to see it is the larger of the two tables…
[root@cmhlpdlkedat01 ~]# ls -lrt /proc/3412/fd | grep 2231
lrwx------ 1 yarn hadoop 64 Apr 10 08:32 429 -> socket:[34622312]
lr-x------ 1 yarn hadoop 64 Apr 10 08:47 2231 -> /mnt/hdfs/hadoop/yarn/local/usercache/root/appcache/application_1428633698169_0025/container_1428633698169_0025_01_000004/tmp/hive-rowcontainer7779433895197233164/RowContainer4530514485187724697.tmp
[root@cmhlpdlkedat01 ~]# tail -f /mnt/hdfs/hadoop/yarn/local/usercache/root/appcache/application_1428633698169_0025/container_1428633698169_0025_01_000004/tmp/hive-rowcontainer7779433895197233164/RowContainer4530514485187724697.tmp
2014-05-16T
2014-05-16¦
2014-05-16¦?
2014-03-13¦
2014-03-13
2014-03-13¦
2014-03-13V
2014-03-13
2014-03-13
q
2014-03-13
We then decide to get a thread dump for the JVM. First of all, notice the name of the JVM is TezChild, which is a tip off that you are runnbing hive code on a given server. Again, there are other ways, this is just one of them.
[root@cmhlpdlkedat01 yarn]# su - yarn
[yarn@cmhlpdlkedat01 ~]$ jps
16082 NodeManager
663 Jps
3393 TezChild
[yarn@cmhlpdlkedat01 ~]$ printf "%x\n" 3412
d54
[yarn@cmhlpdlkedat01 ~]$ jstack 3393 | awk '{if ($0 ~ "0xd54") {i = 1;print $0} else if (i == 1 && $0 != "") {print $0} else if (i == 1 && $0 == "") {exit}}'
"TezChild" daemon prio=10 tid=0x00007f5e886c8000 nid=0xd54 runnable [0x00007f5e7d17c000]
java.lang.Thread.State: RUNNABLE
at java.io.DataInputStream.readFully(DataInputStream.java:195)
at org.apache.hadoop.io.BytesWritable.readFields(BytesWritable.java:180)
at org.apache.hadoop.io.serializer.WritableSerialization$WritableDeserializer.deserialize(WritableSerialization.java:71)
at org.apache.hadoop.io.serializer.WritableSerialization$WritableDeserializer.deserialize(WritableSerialization.java:42)
at org.apache.hadoop.io.SequenceFile$Reader.deserializeValue(SequenceFile.java:2245)
at org.apache.hadoop.io.SequenceFile$Reader.getCurrentValue(SequenceFile.java:2218)
- locked <0x00000000f68a80f0> (a org.apache.hadoop.io.SequenceFile$Reader)
at org.apache.hadoop.mapred.SequenceFileRecordReader.getCurrentValue(SequenceFileRecordReader.java:109)
- locked <0x00000000f68a80c8> (a org.apache.hadoop.mapred.SequenceFileRecordReader)
at org.apache.hadoop.mapred.SequenceFileRecordReader.next(SequenceFileRecordReader.java:84)
- locked <0x00000000f68a80c8> (a org.apache.hadoop.mapred.SequenceFileRecordReader)
at org.apache.hadoop.hive.ql.exec.persistence.RowContainer.nextBlock(RowContainer.java:360)
at org.apache.hadoop.hive.ql.exec.persistence.RowContainer.next(RowContainer.java:267)
at org.apache.hadoop.hive.ql.exec.persistence.RowContainer.next(RowContainer.java:74)
at org.apache.hadoop.hive.ql.exec.CommonJoinOperator.genUniqueJoinObject(CommonJoinOperator.java:644)
at org.apache.hadoop.hive.ql.exec.CommonJoinOperator.genUniqueJoinObject(CommonJoinOperator.java:654)
at org.apache.hadoop.hive.ql.exec.CommonJoinOperator.checkAndGenObject(CommonJoinOperator.java:750)
at org.apache.hadoop.hive.ql.exec.CommonMergeJoinOperator.joinObject(CommonMergeJoinOperator.java:248)
at org.apache.hadoop.hive.ql.exec.CommonMergeJoinOperator.joinOneGroup(CommonMergeJoinOperator.java:213)
at org.apache.hadoop.hive.ql.exec.CommonMergeJoinOperator.processOp(CommonMergeJoinOperator.java:196)
at org.apache.hadoop.hive.ql.exec.tez.ReduceRecordSource$GroupIterator.next(ReduceRecordSource.java:328)
at org.apache.hadoop.hive.ql.exec.tez.ReduceRecordSource.pushRecord(ReduceRecordSource.java:258)
at org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.run(ReduceRecordProcessor.java:168)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:163)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
[yarn@cmhlpdlkedat01 ~]$
If we again run the thread dump, we see a different call stack, with very interesting names for the classes and methods…
[yarn@cmhlpdlkedat01 ~]$ jstack 3393 | awk '{if ($0 ~ "0xd54") {i = 1;print $0} else if (i == 1 && $0 != "") {print $0} else if (i == 1 && $0 == "") {exit}}'
"TezChild" daemon prio=10 tid=0x00007f5e886c8000 nid=0xd54 runnable [0x00007f5e7d17b000]
java.lang.Thread.State: RUNNABLE
at sun.nio.cs.UTF_8.updatePositions(UTF_8.java:78)
at sun.nio.cs.UTF_8$Encoder.encodeArrayLoop(UTF_8.java:564)
at sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:619)
at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:561)
at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:783)
at org.apache.hadoop.io.Text.encode(Text.java:450)
at org.apache.hadoop.io.Text.set(Text.java:198)
at org.apache.hadoop.hive.ql.udf.UDFSubstr.evaluate(UDFSubstr.java:78)
at sun.reflect.GeneratedMethodAccessor5.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.hive.ql.exec.FunctionRegistry.invoke(FunctionRegistry.java:1235)
at org.apache.hadoop.hive.ql.udf.generic.GenericUDFBridge.evaluate(GenericUDFBridge.java:182)
at org.apache.hadoop.hive.ql.exec.ExprNodeGenericFuncEvaluator._evaluate(ExprNodeGenericFuncEvaluator.java:185)
at org.apache.hadoop.hive.ql.exec.ExprNodeEvaluator.evaluate(ExprNodeEvaluator.java:77)
at org.apache.hadoop.hive.ql.exec.ExprNodeEvaluator.evaluate(ExprNodeEvaluator.java:65)
at org.apache.hadoop.hive.ql.exec.KeyWrapperFactory$ListKeyWrapper.getNewKey(KeyWrapperFactory.java:113)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.processOp(GroupByOperator.java:784)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)
at org.apache.hadoop.hive.ql.exec.SelectOperator.processOp(SelectOperator.java:84)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)
at org.apache.hadoop.hive.ql.exec.CommonJoinOperator.internalForward(CommonJoinOperator.java:638)
at org.apache.hadoop.hive.ql.exec.CommonJoinOperator.genUniqueJoinObject(CommonJoinOperator.java:651)
at org.apache.hadoop.hive.ql.exec.CommonJoinOperator.genUniqueJoinObject(CommonJoinOperator.java:654)
at org.apache.hadoop.hive.ql.exec.CommonJoinOperator.checkAndGenObject(CommonJoinOperator.java:750)
at org.apache.hadoop.hive.ql.exec.CommonMergeJoinOperator.joinObject(CommonMergeJoinOperator.java:248)
at org.apache.hadoop.hive.ql.exec.CommonMergeJoinOperator.joinOneGroup(CommonMergeJoinOperator.java:213)
at org.apache.hadoop.hive.ql.exec.CommonMergeJoinOperator.processOp(CommonMergeJoinOperator.java:196)
at org.apache.hadoop.hive.ql.exec.tez.ReduceRecordSource$GroupIterator.next(ReduceRecordSource.java:328)
at org.apache.hadoop.hive.ql.exec.tez.ReduceRecordSource.pushRecord(ReduceRecordSource.java:258)
at org.apache.hadoop.hive.ql.exec.tez.ReduceRecordProcessor.run(ReduceRecordProcessor.java:168)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:163)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
[yarn@cmhlpdlkedat01 ~]$
Not an answer, but it is additional info.