In earlier versions of hadoop, the namenode was the Achilles heel. While there was the option of failing over to a secondary namenode, this required manual intervention, or heavy scripting at best. Even then, failover wasn’t instantaneous.
With Hadoop 0.23 and later releases, a primary and standby namenode configuration was introduced. This required very little out of the box configuration, with tools such as ambari providing a next/next/next click setup.
This post simply shows how it works, with an example that shows each node in the configuration. We then start a job that will require access to the primary namenode, and terminate its process. We see that our job runs to completion.
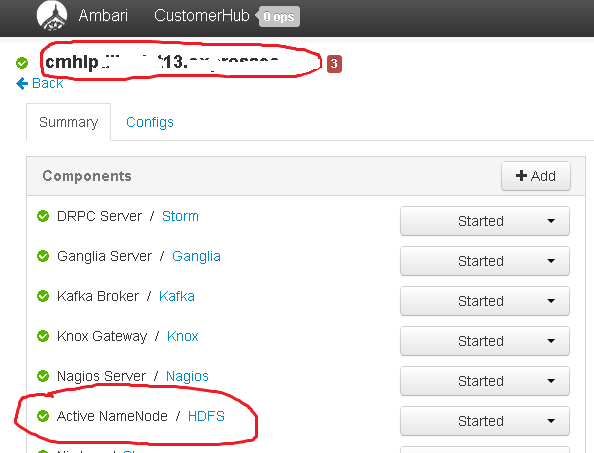
First, we show our primary namenode..
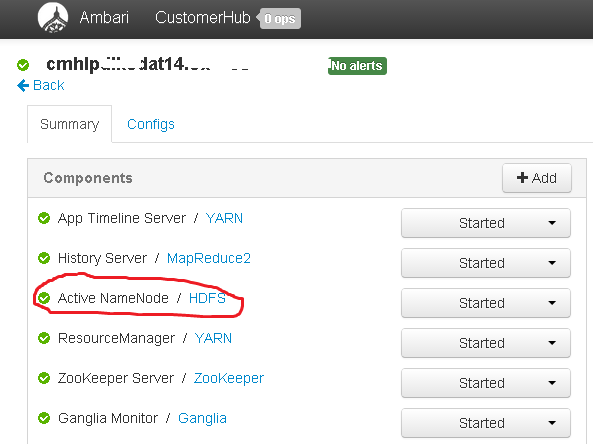
…and then, our secondary namenode…
We then compile our simple class shown below…
import java.io.*;
import java.util.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
public class HDFSFileBlocks {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path file = new Path(args[0]);
FileStatus fileStatus = fs.getFileStatus(file);
BlockLocation[] blocks = fs.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
for (int i = 0; i < blocks.length; i++) {
System.out.println(blocks[i].toString());
}
BufferedReader br=new BufferedReader(new InputStreamReader(fs.open(file)));
String line=br.readLine();
while (line != null){
System.out.println(line);
line=br.readLine();
}
fs.close();
}
}
...and run the job, during which time we terminate the primary namenode on node 14...
[root@cmhl******07 ~]# export CLASSPATH=$(yarn classpath)
[root@cmhl******07 ~]# javac HDFSFileBlocks.java
[root@cmhl******07 ~]# cat manifest.txt
Manifest-Version: 1.0
Main-Class: HDFSFileBlocks
[root@cmhl******07 ~]# jar cfm myjar.jar manifest.txt HDFSFileBlocks.class
[root@cmhl******07 ~]# hadoop jar myjar.jar /tmp/splunk__106646.esw3c_S.201311290900-1000-0 > /dev/null & ssh cmhl*******14 "kill -9 \$(ps -ef | grep java | grep -v grep | egrep NameNode\$ | awk '{print \$2}')"[4] 13071[3] Done hadoop jar myjar.jar /tmp/splunk__106646.esw3c_S.201311290900-1000-0 > /dev/null
[root@cmhl******07 ~]#
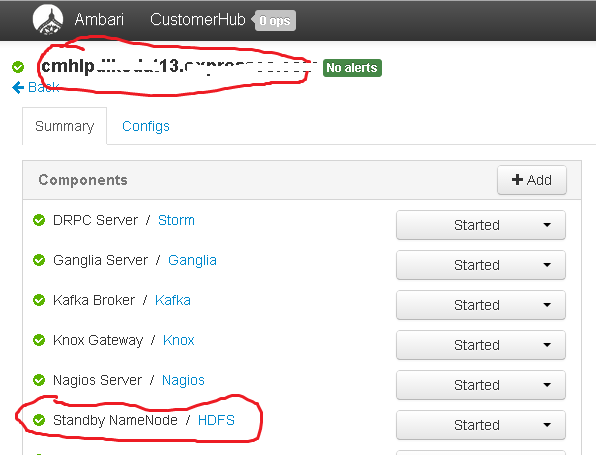
We see that our standby namenode is stopped...
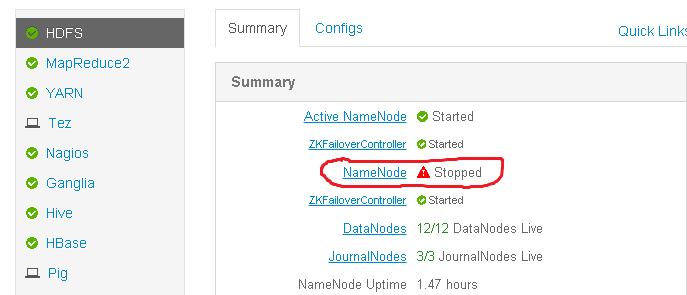
...and also see the primary namenode is now on node 13...